Les prérequis :
- Python : Je fais du python3.
- MariaDB
- Grafana : J’utilise la version 5.0.0.
- Linux : J’utilise Ubuntu 18
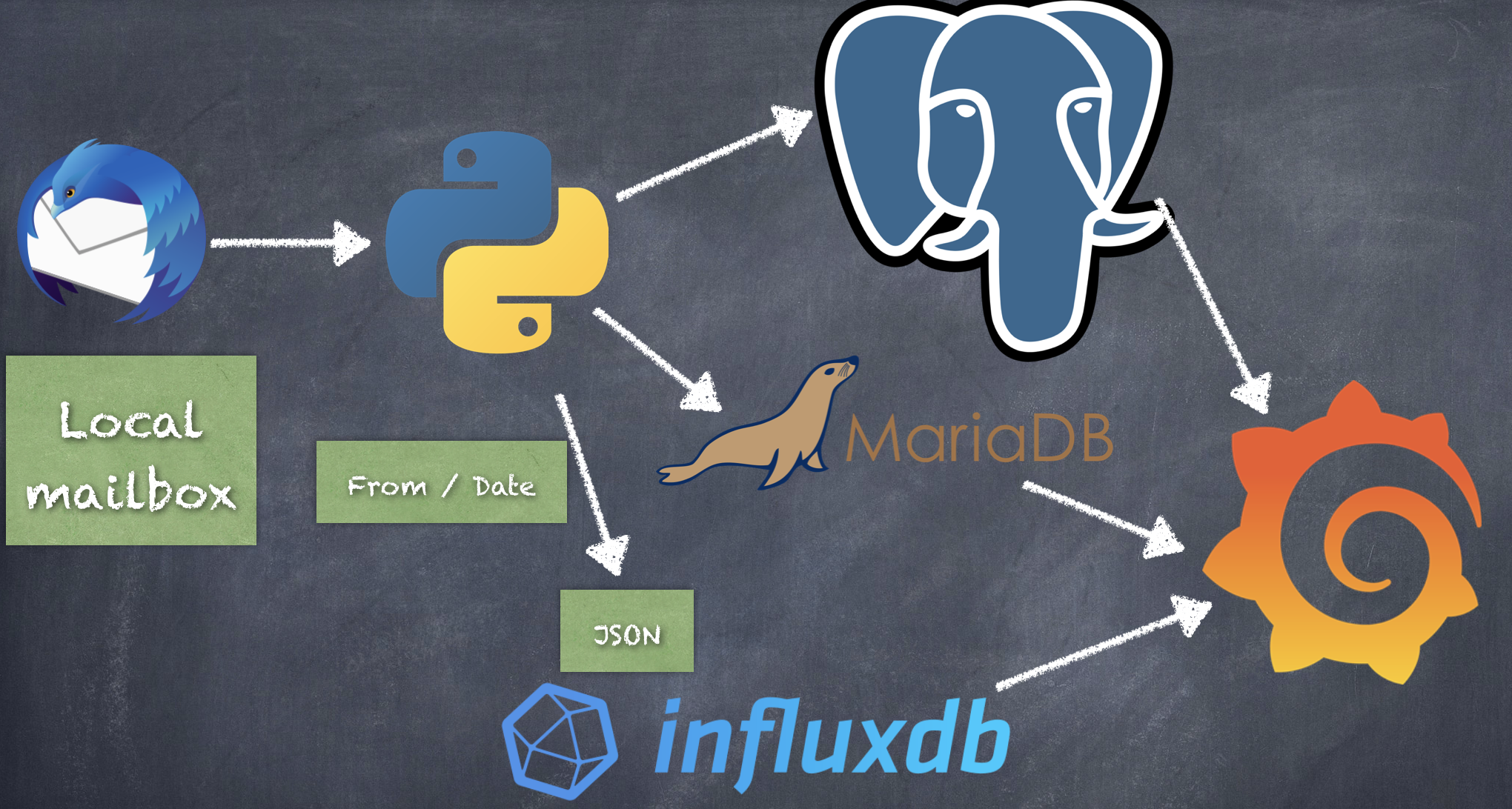
Voici donc ce que j’ai fait pour avoir mes données sous Grafana.
Etape 1 :
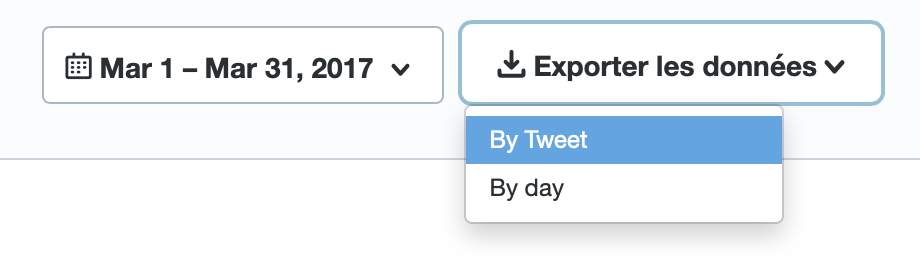
Je vais sur Twitter Analytics : https://analytics.twitter.com/about et je télécharge les fichiers CSV (By Tweet, et non By Day). Normalement j’ai un fichier CSV par mois.
Etape 2 :
Je concatène tous les fichiers CSV dans un seul fichier en supprimant les entetes :
cat tweet_activity_metrics_CYBERNEURONES_20* | grep -v "Identifiant du" > input.csv
Etape 3 :
Je lance le programme en Python pour mettre les données sous MariaDB. A noter que j’ai fait une base et un login pour Twitter avant :
-> create database TWITTERS;
-> CREATE USER 'twitter'@'localhost' IDENTIFIED BY 'twitter';
-> GRANT ALL PRIVILEGES ON TWITTERS.* TO 'twitter'@'localhost';
-> FLUSH PRIVILEGES;
Le programme en Python :
#! /usr/bin/env python3
# ~*~ utf-8 ~*~
import csv
from datetime import datetime
import mysql.connector
from mysql.connector import errorcode
from mysql.connector import (connection)
cnx = connection.MySQLConnection(user='twitter', password='twitter',
host='127.0.0.1',
database='TWITTERS')
cursor = cnx.cursor();
now = datetime.now().date();
#cursor.execute("DROP TABLE TWITTER;");
#cursor.execute("CREATE TABLE TWITTER (IDENTIFIANT varchar(30) UNIQUE,PERMALIEN varchar(200),TEXTE varchar(500),DATE datetime,IMPRESSION float,ENGAGEMENT float,TAUX_ENGAGEMENT float, RETWEET float,REPONSE float, JAIME float, CLIC_PROFIL float, CLIC_URL float, CLIC_HASTAG float, OUVERTURE_DETAIL float, CLIC_PERMALIEN float, OUVERTURE_APP int, INSTALL_APP int, ABONNEMENT int, EMAIL_TWEET int, COMPOSER_NUMERO int, VUE_MEDIA int, ENGAGEMENT_MEDIA int);");
cursor.execute("DELETE FROM TWITTER");
with open('input.csv', 'r') as csvfile:
reader = csv.reader(csvfile, quotechar='"')
for row in reader:
MyDate=row[3].replace(" +0000", ":00")
MyTexte=row[2].replace("'", " ")
MyTexte=MyTexte.replace(",", " ")
MyC4=row[4].replace("Infinity", "0")
MyC5=row[5].replace("Infinity", "0")
MyC6=row[6].replace("Infinity", "0")
MyC6=MyC6.replace("NaN", "0")
MyC7=row[7].replace("Infinity", "0")
try :
cursor.execute("INSERT INTO TWITTER (IDENTIFIANT,PERMALIEN,TEXTE,DATE,IMPRESSION,ENGAGEMENT,TAUX_ENGAGEMENT,RETWEET,REPONSE, JAIME, CLIC_PROFIL, CLIC_URL, CLIC_HASTAG, OUVERTURE_DETAIL, CLIC_PERMALIEN, OUVERTURE_APP, INSTALL_APP, ABONNEMENT, EMAIL_TWEET, COMPOSER_NUMERO, VUE_MEDIA, ENGAGEMENT_MEDIA) VALUES ('"+row[0]+"', '"+row[1]+"', '"+MyTexte+"','"+MyDate+"', "+MyC4+", "+MyC5+", "+MyC6+", "+MyC7+", "+row[8]+","+row[9]+", "+row[10]+", "+row[11]+","+row[12]+","+row[13]+","+row[14]+","+row[15]+","+row[16]+","+row[17]+","+row[18]+","+row[19]+","+row[20]+","+row[21]+");");
except mysql.connector.Error as err:
print("Something went wrong: {}".format(err))
if err.errno == errorcode.ER_BAD_TABLE_ERROR:
print("Creating table TWITTER")
else:
None
cnx.commit();
cursor.close();
cnx.close();
# END
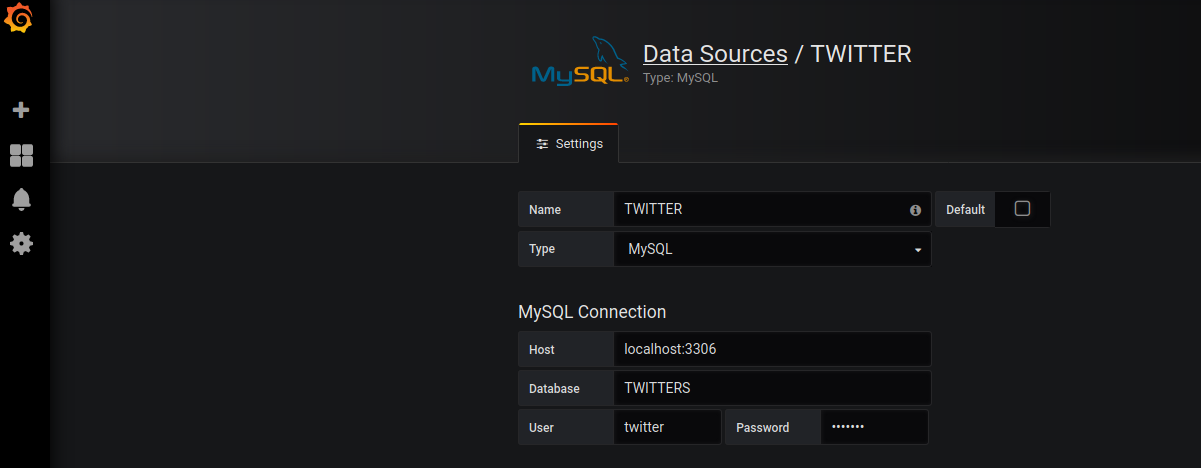
Etape 4 :
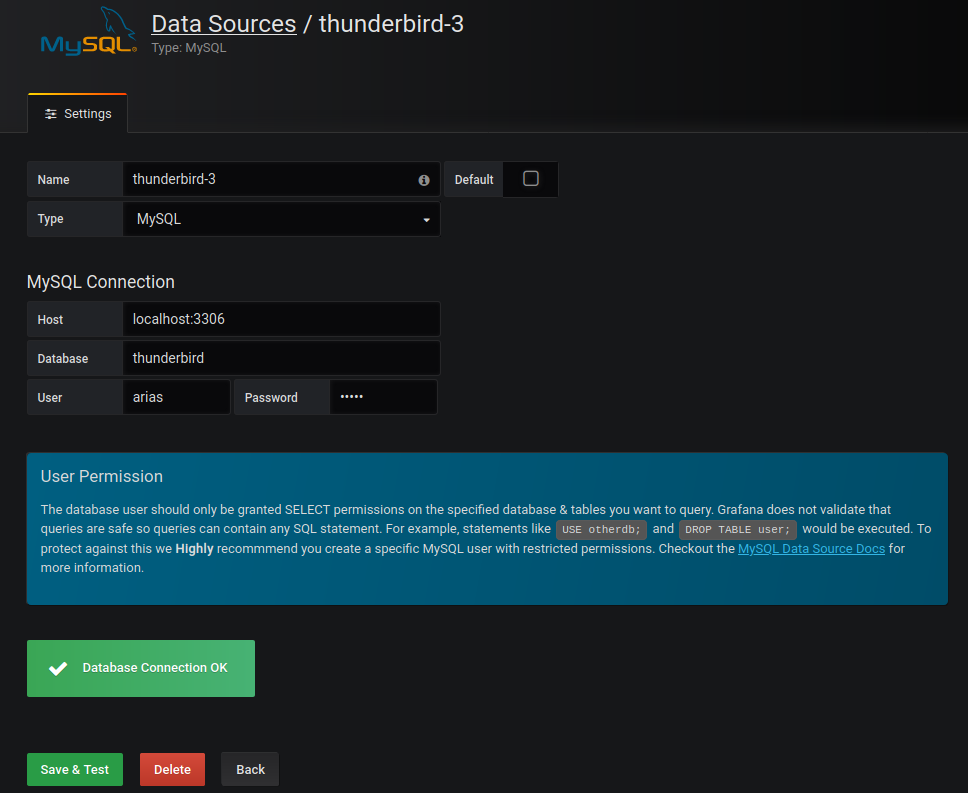
Je configure Grafana pour avoir accès à MariaDB :
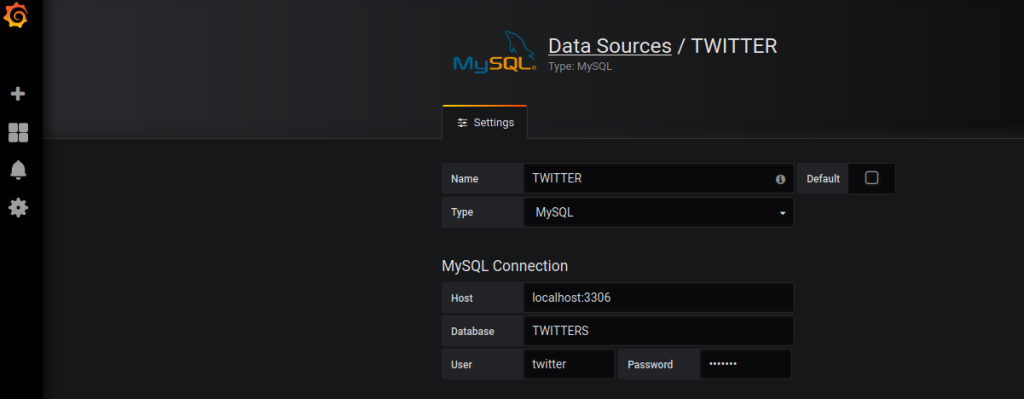 Etape 5 :
Etape 5 :
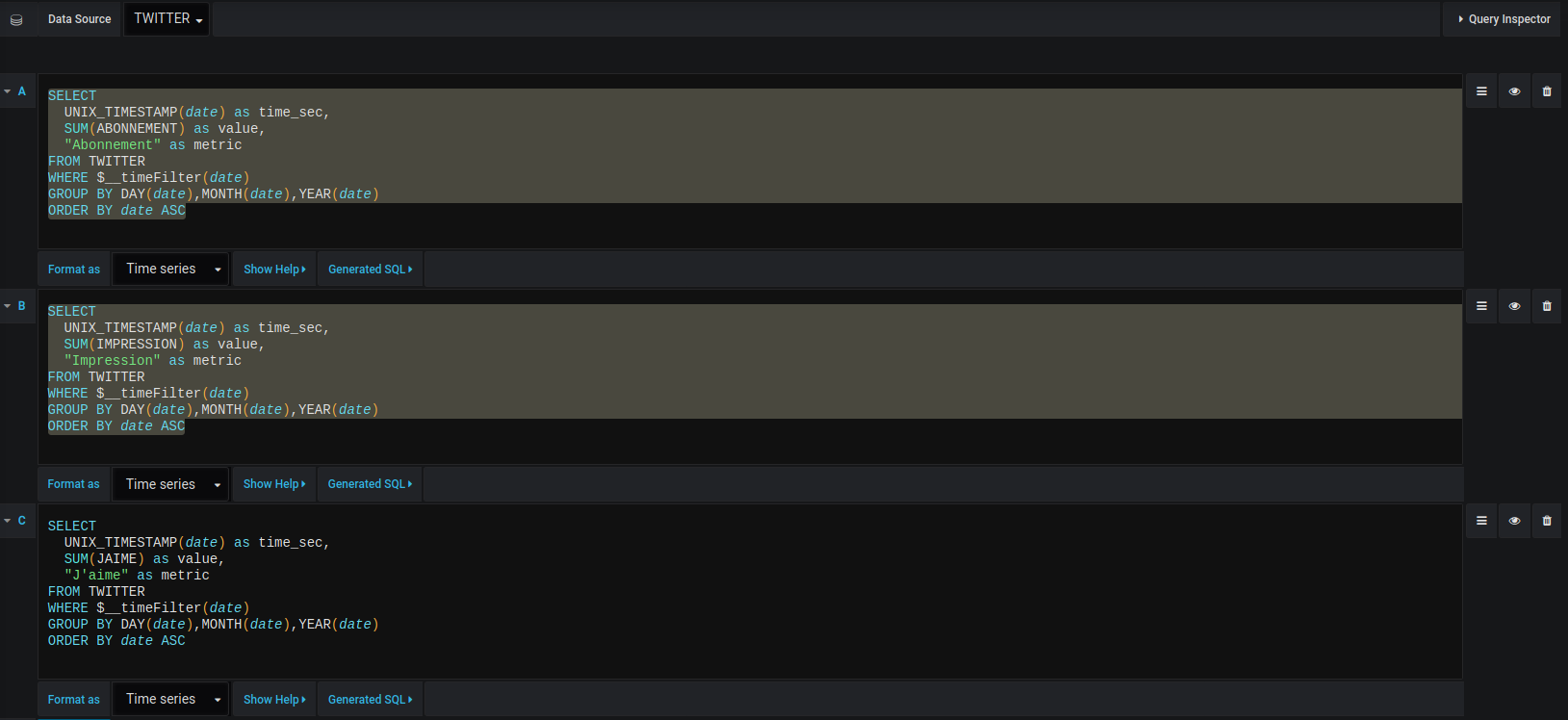
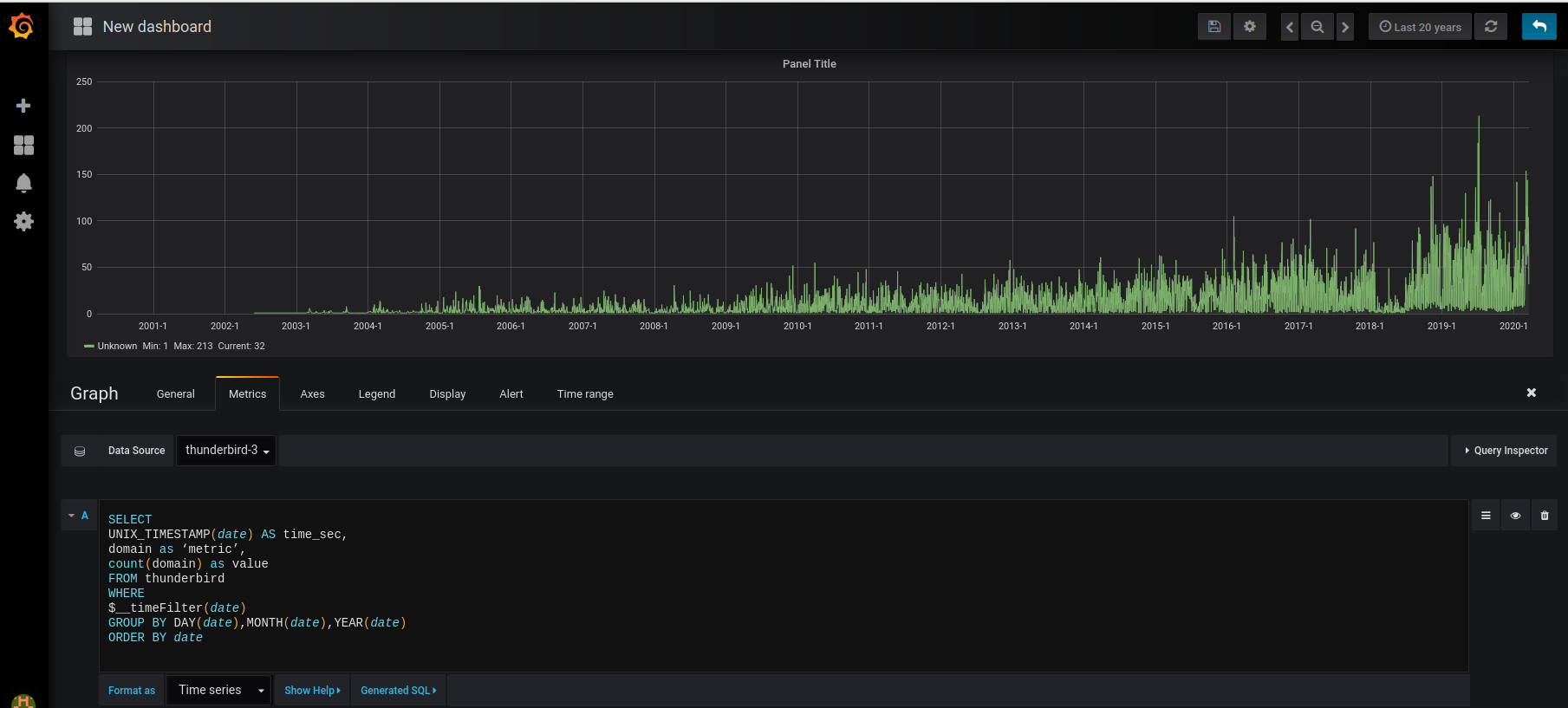
Faire les graphiques :
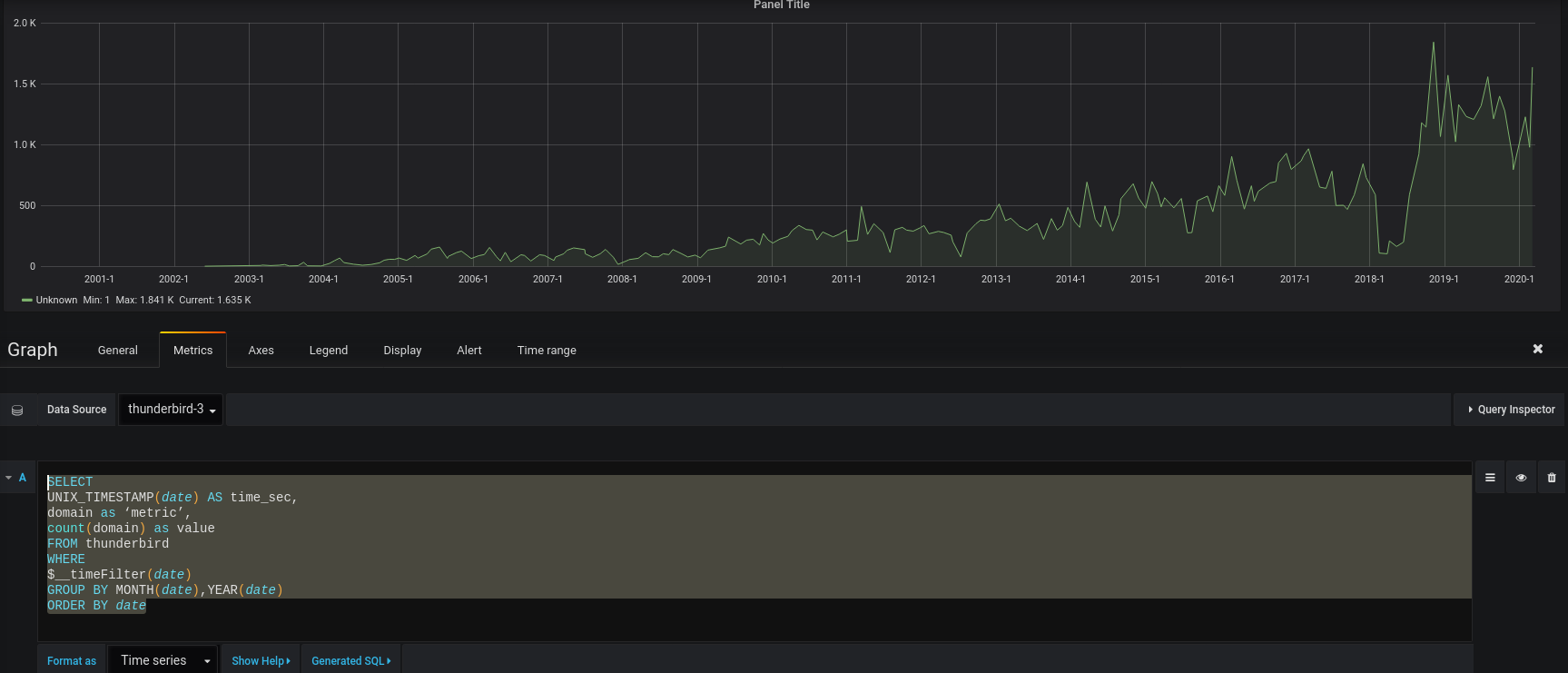
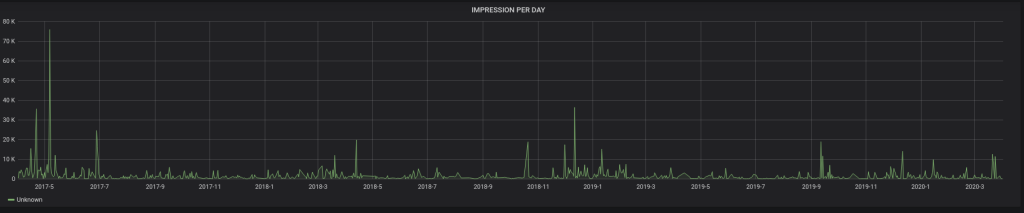
– Pour le nombre d’impression par jour :
SELECT
UNIX_TIMESTAMP(date) as time_sec,
SUM(IMPRESSION) as value
FROM TWITTER
WHERE $__timeFilter(date)
GROUP BY DAY(date),MONTH(date),YEAR(date)
ORDER BY date ASC
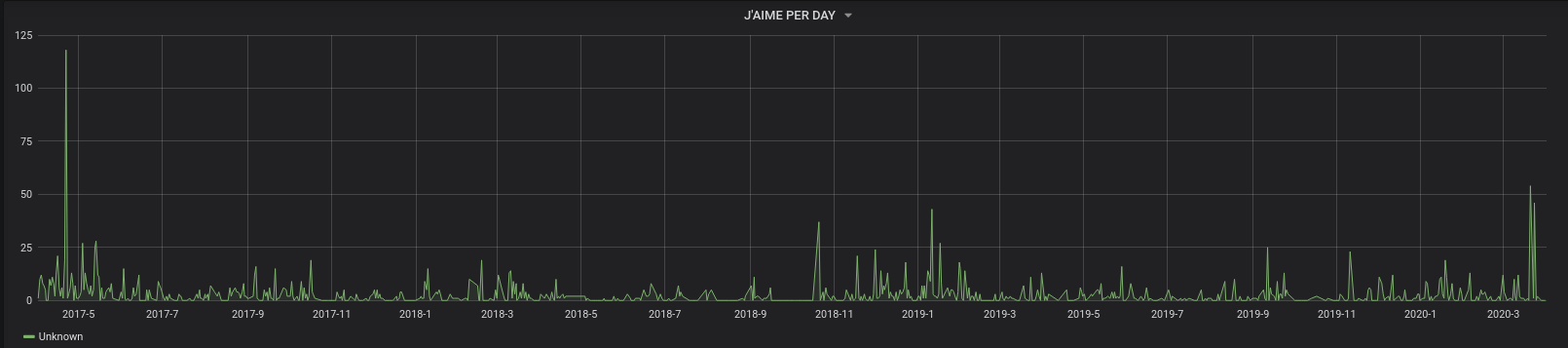
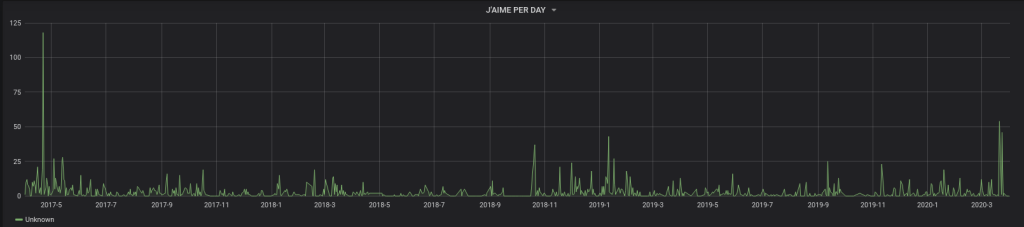
– Pour le nombre de « J’aime » par jour :
SELECT
UNIX_TIMESTAMP(date) as time_sec,
SUM(JAIME) as value
FROM TWITTER
WHERE $__timeFilter(date)
GROUP BY DAY(date),MONTH(date),YEAR(date)
ORDER BY date ASC
– Pour le nombre de « Clic sur profil » par jour :
SELECT
UNIX_TIMESTAMP(date) as time_sec,
SUM(CLIC_PROFIL) as value
FROM TWITTER
WHERE $__timeFilter(date)
GROUP BY DAY(date),MONTH(date),YEAR(date)
ORDER BY date ASC
 – Pour le nombre d’Abonnement par jour :
– Pour le nombre d’Abonnement par jour :
SELECT
UNIX_TIMESTAMP(date) as time_sec,
SUM(ABONNEMENT) as value
FROM TWITTER
WHERE $__timeFilter(date)
GROUP BY DAY(date),MONTH(date),YEAR(date)
ORDER BY date ASC
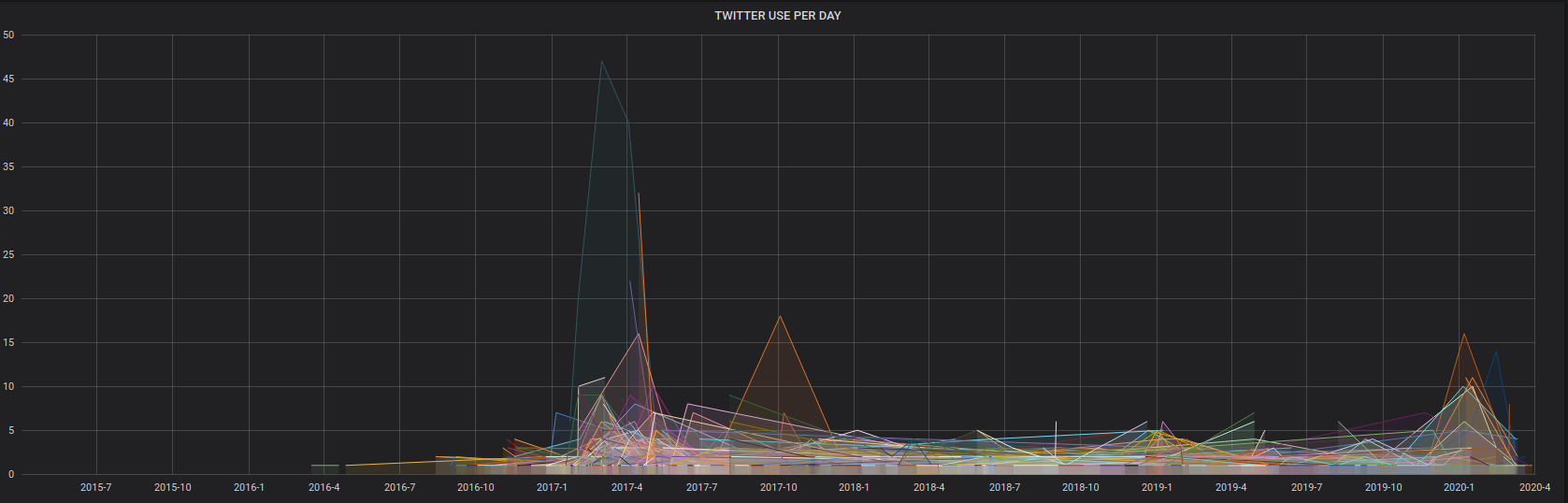
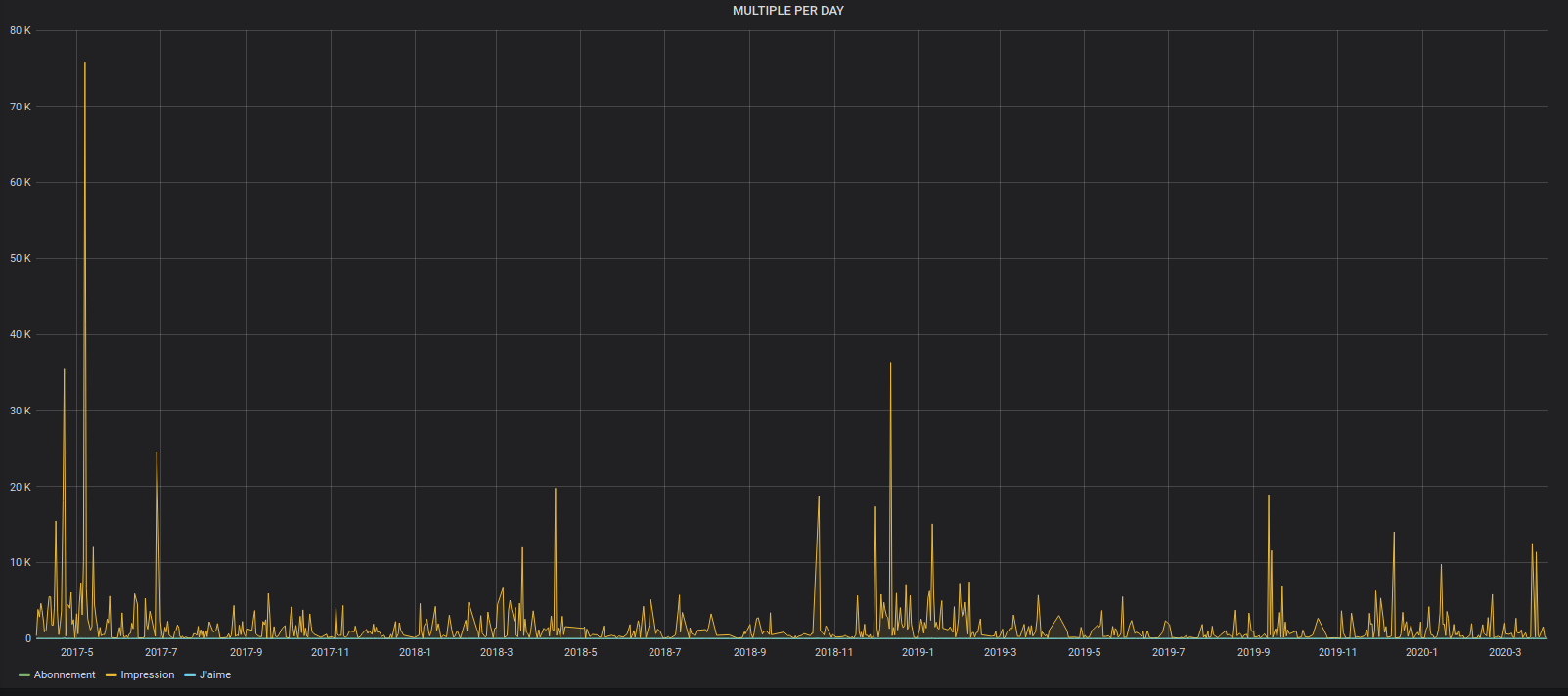
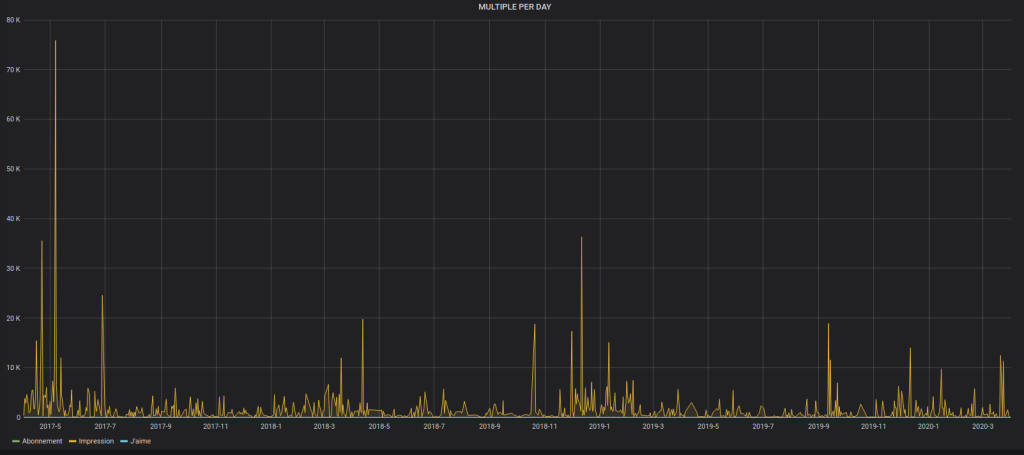
 Il est aussi possible de mettre plusieurs courbes sur le même graphe:
Il est aussi possible de mettre plusieurs courbes sur le même graphe:
J’aime ça :
J’aime chargement…

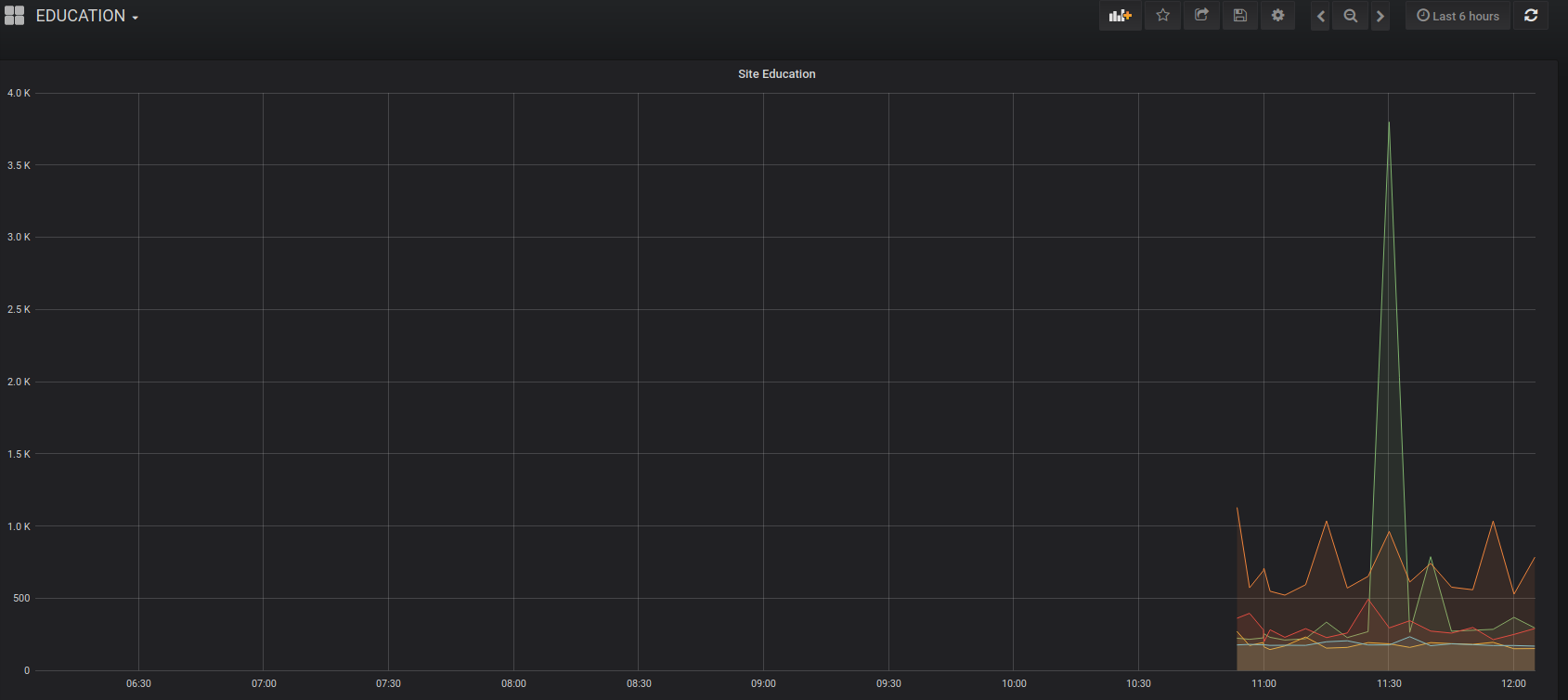 A noter que j’ai du mal à comprendre l’utilisation des sites de Google, cela insite les élèves à se distraire … Misère.
A noter que j’ai du mal à comprendre l’utilisation des sites de Google, cela insite les élèves à se distraire … Misère. Pareil pour les sites web, pourquoi ne pas utiliser https://frama.site/ à la place de Google ?
Pareil pour les sites web, pourquoi ne pas utiliser https://frama.site/ à la place de Google ?