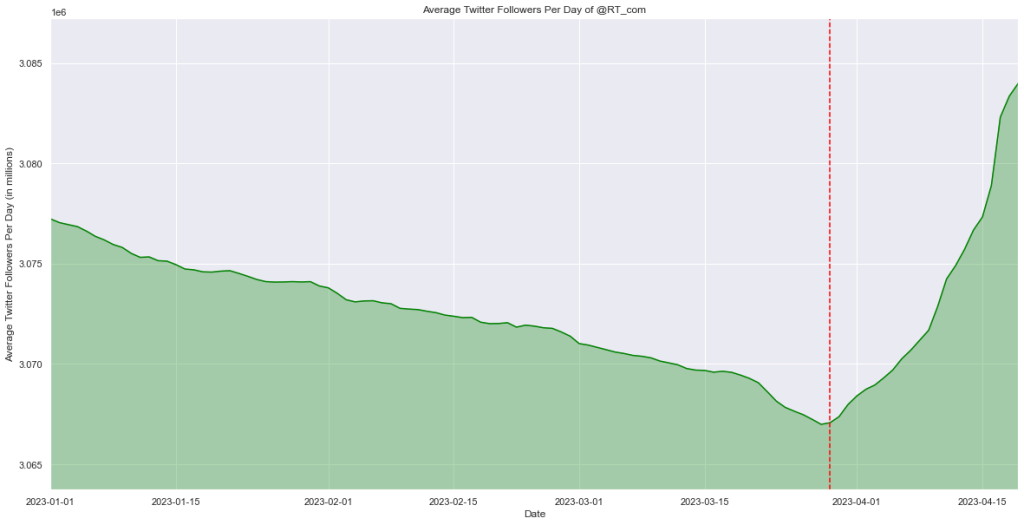
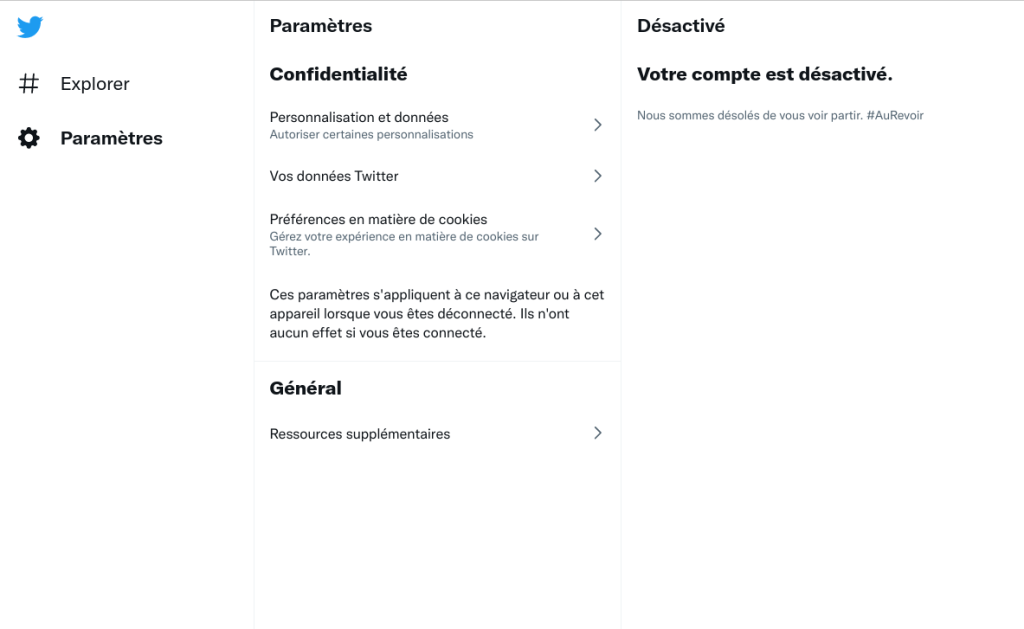
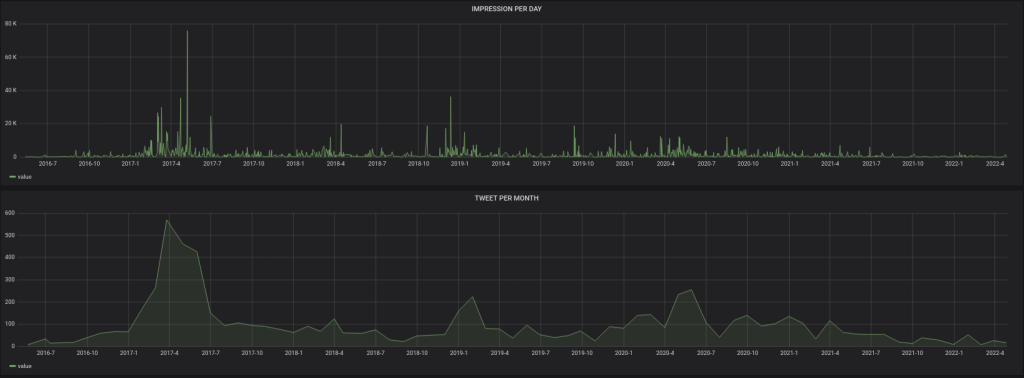
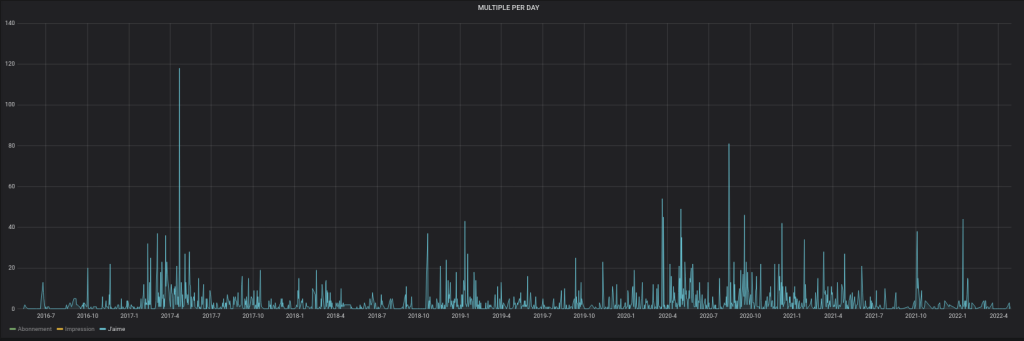
Je vais donc cloturer le compte CYBERNEURONES : https://twitter.com/CYBERNEURONES , que j’avais rejoint en septembre 2014. Actuellement je passe trop de temps à bloquer des comptes. Twitter est pourri par la désinformation qui est RT, à la base de la désinformation : Valeurs Actuelles, CNews, RT, Sputnik, France Soir, Sud Radio … Hanouna, Bercoff, Rioufol, Praud, Aberkane, Poulin, Di Vizio … mais aussi l’extreme droite …. Je pense donc qu’avec le changement de propriétaire cela va être pire. Misère.
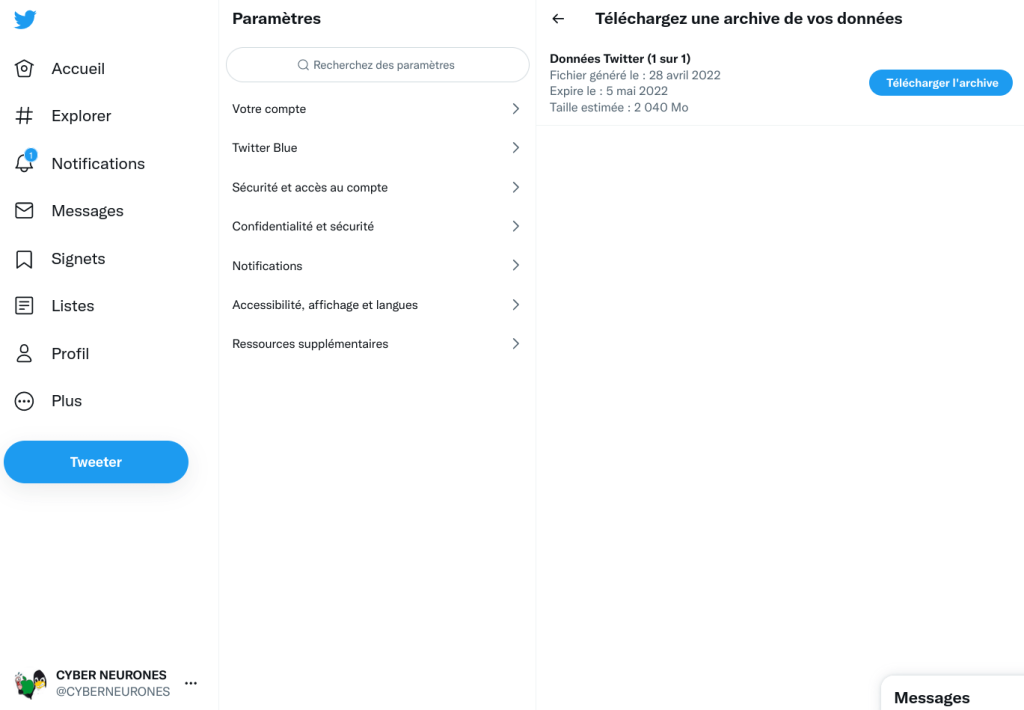
J’ai demandé à Twitter toutes mes données, ensuite je ferais la cloture du compte.
 Voici la liste des comptes que je suivais et que j’espère voir un jour sur Mastodon :
Voici la liste des comptes que je suivais et que j’espère voir un jour sur Mastodon :
– Catégorie Dev : @DevoxxFR @OSXP_Paris @cq94 @RivieraDEV @solutionslinux
– Catégorie Politique : @PartiPirate @ZelenskyyUa @ca_ginesy @JoeBiden @pbeyssac @cedric_o @Sonia_Krimi @M_Orphelin @PaulaForteza @babgi @AlexTaylorNews @AAzoulay @ar_leroy @davidlisnard @EPhilippe_LH @VillaniCedric @CReverso06 @Maitre_Eolas @Projet_Arcadie @EmmanuelMacron @ncadene @rglucks1 @LaurenceParisot @JC_Picard @axellelemaire @JeanLeonetti @anticor_org @palais_au @grebert @gchampeau @GerardAraud @malopedia @guyverhofstadt @xavier_alberti
– Catégorie Politique locale : @MarikaRoman @PavandesBois @CJoussemet @sdeschaintres @Alexia_Barrier @EricPAUGET1 @guillaumelecoz @JPDERMIT @Guilaine_Debras @MaxBiot
– Catégorie Securité : @CERT_FR @bearstech @sorianotech @fs0c131y
– Catégorie Course : @kinesiologui @ITRA_trail @kilianj
– Catégorie Rugby : @FGalthie @EspritdelaRegle @JusticierOvale @BoucherieOvalie @FranceRugby @CastresRugby
– Catégorie Journaliste : @Curiolog @tristanmf @LUppsala @christopheconte @clemovitch @WTFake_ @OhmarieCS @samuellaurent @AfpFactuel @GeWoessner @pierrebrt @AdrienSnk @lofejoma @GeoClavel @askolovitchC @Alex_Boudet @thomassnegaroff @SamGontier @paul_denton @S_Tronche @mompontet @In_Feuerstein @cocale @HConstanty @jmaphatie @decodeurs @SophiaAram @AnnickCojean @GrablyR @SylvainTronchet @JulienPain @Piedminu @PascaleClark @MarionVanR
– Catégorie Vélo : @PacaVelo @maxch06 @ChoisirLeVelo @M_Chassignet
– Catégorie Santé : @barriere_dr @DgCostagliola @DrGomi @OSS117_Helsinki @Le___Doc @EricBillyFR @EricTopol
– Catégorie Science : @NicoMartinFC @Damkyan_Omega @alexandra_gros @le_science4all @Vlanx
– Catégorie Emission : @cavousf5 @Qofficiel @Ccesoir
J’aime ça :
J’aime chargement…