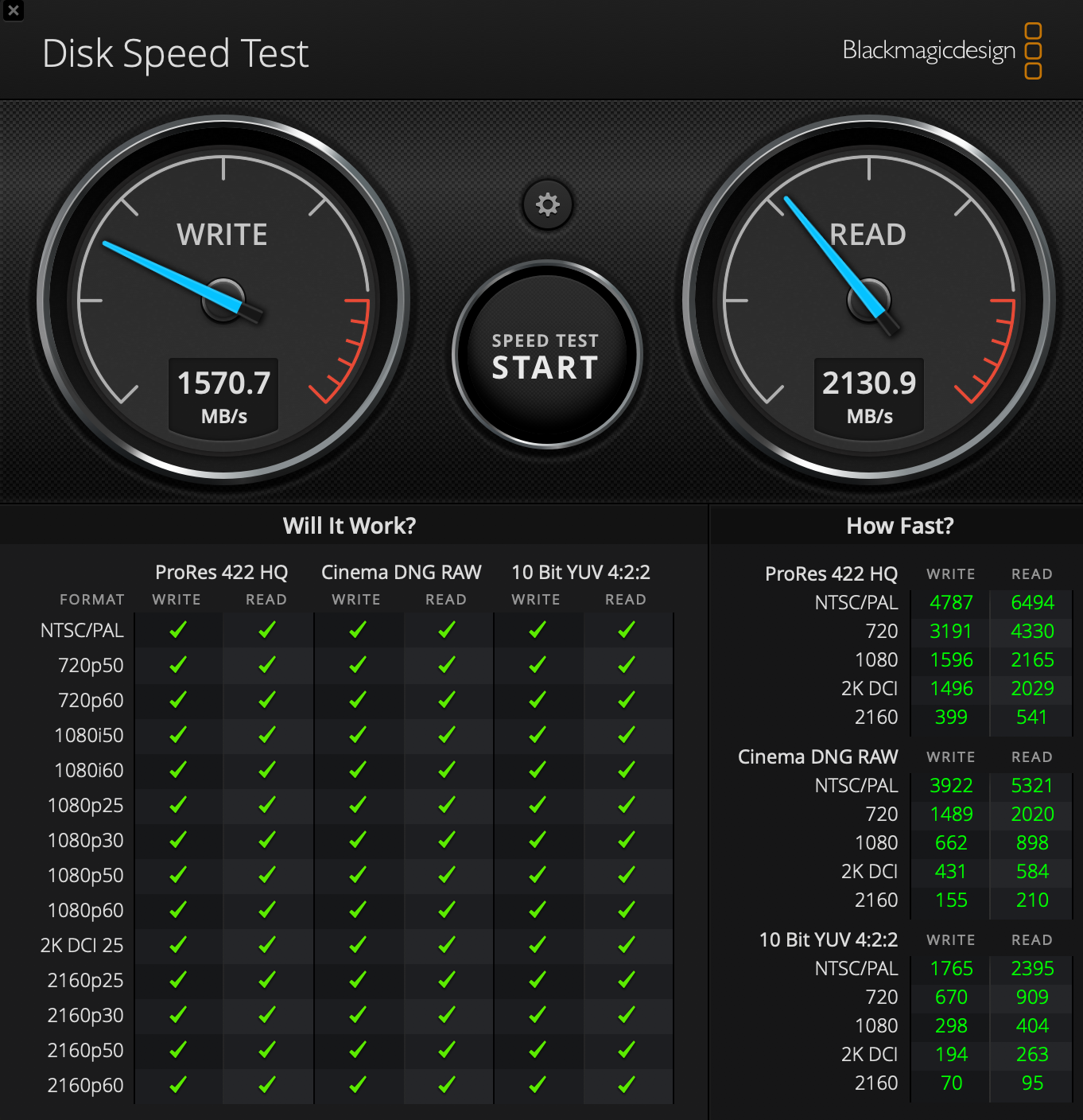
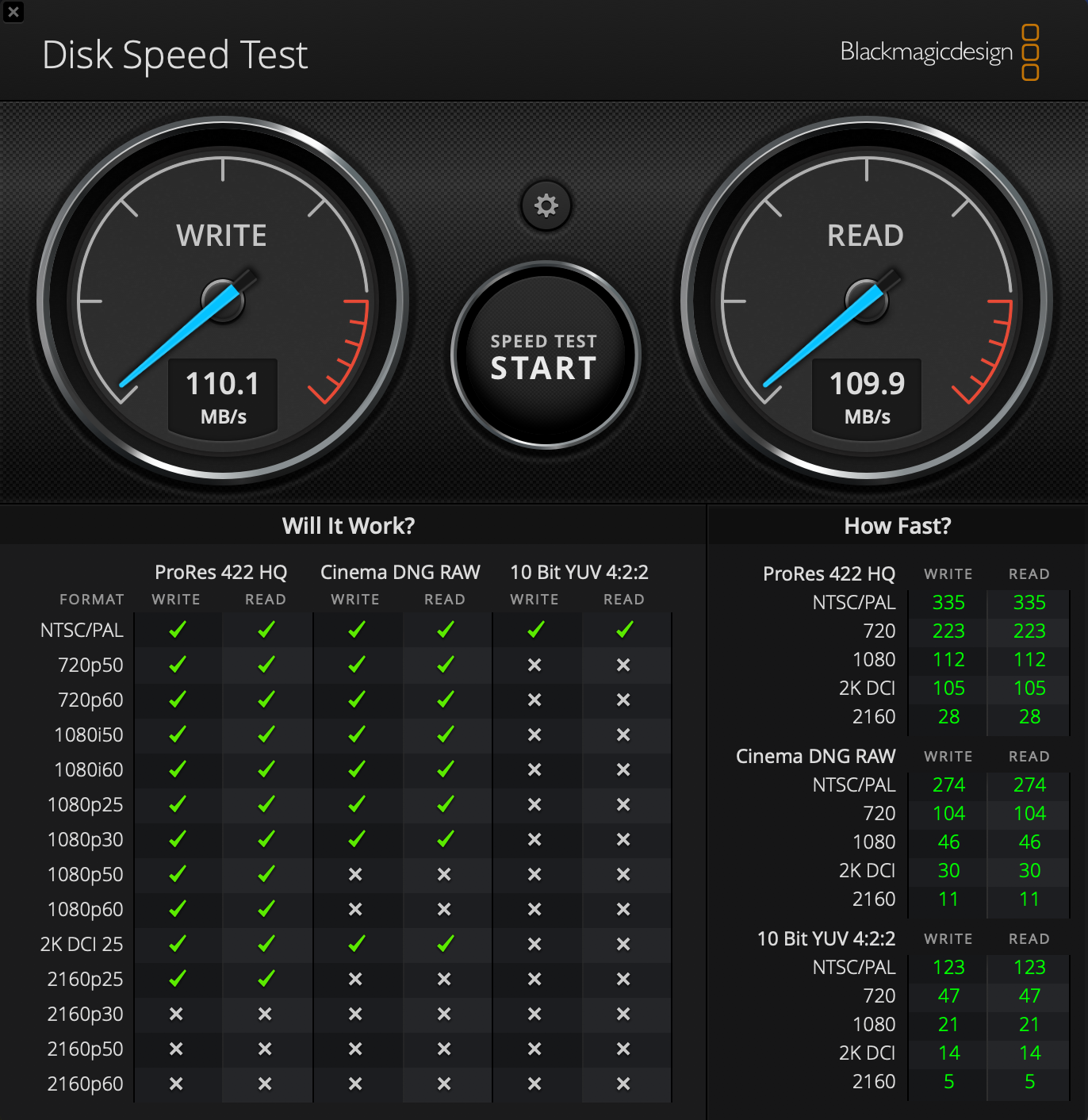
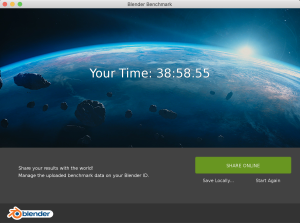
Nouveau test de charge cette fois avec un MacBook Pro (15 pouces, mi-2012) : Mojave 10.14.6 / 2,3 GHz Intel Core i7 / 16 Go 1600 MHz DDR3 / NVIDIA GeForce GT 650M 512 Mo / Intel HD Graphics 4000 1536 Mo . C’est pour faire suite à ce premier test : https://www.cyber-neurones.org/2019/12/macos-macbook-pro-15-inch-2017-benchmark-avec-blender/ : Catalina 10.15.1 (19B88) / MacBook Pro (15-inch, 2017) / 2,9 GHz Intel Core i7 quatre cœurs / 16 Go 2133 MHz LPDDR3. Entre les deux portables il y a 5 ans d’anciennetés .
Les résultats : En 5 ans on a divisé par deux ….
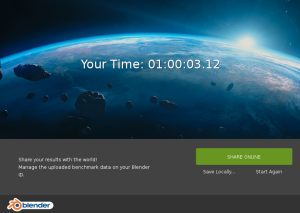

Les résultats dans le détails :
{
"benchmark_client": {
"client_version": "1.0b2"
},
"blender_version": {
"build_commit_date": "2018-03-22",
"build_commit_time": "14:10",
"build_date": "2018-03-22",
"build_hash": "f4dc9f9",
"build_time": "21:48:25",
"version": "2.79 (sub 0)"
},
"device_info": {
"compute_devices": [
"Intel Core i7-3615QM CPU @ 2.30GHz"
],
"device_type": "CPU",
"num_cpu_threads": 8
},
"scenes": [
{
"name": "bmw27",
"stats": {
"device_memory_usage": 140.55,
"device_peak_memory": 140.56,
"pipeline_render_time": 795.28,
"render_time_no_sync": 788.435,
"result": "OK",
"total_render_time": 793.803
}
},
{
"name": "classroom",
"stats": {
"device_memory_usage": 295.71,
"device_peak_memory": 295.77,
"pipeline_render_time": 2810.41,
"render_time_no_sync": 2807.84,
"result": "OK",
"total_render_time": 2809.32
}
}
],
"system_info": {
"bitness": "64bit",
"cpu_brand": "Intel(R) Core(TM) i7-3615QM CPU @ 2.30GHz",
"devices": [
{
"name": "Intel Core i7-3615QM CPU @ 2.30GHz",
"type": "CPU"
},
{
"name": "HD Graphics 4000",
"type": "OPENCL"
},
{
"name": "GeForce GT 650M",
"type": "OPENCL"
}
],
"machine": "x86_64",
"num_cpu_cores": 4,
"num_cpu_sockets": 1,
"num_cpu_threads": 8,
"system": "Darwin"
},
"timestamp": "2019-12-04T12:10:53.339255+00:00"
}
Pour moi le MacBook Pro il lui faut minimum 16 Go de Ram et 512 Go de disque en SSD, ce qui donne un prix très élevé !