J’ai donc pris « Yolo V3 », c’est le modèle le plus fiable. Et j’ai modifier les sources de tracking-yolo-model afin de compter seulement les cyclistes.
Je mets des ID (que j’ai remplacé par Num) seulement sur les cyclistes :
Le source est donc :
(H, W) = (None, None) # input image height and width for the network
writer = None
bicycle = 0
while(True):
ok, image = cap.read()
if not ok:
print("Cannot read the video feed.")
break
if W is None or H is None: (H, W) = image.shape[:2]
blob = cv.dnn.blobFromImage(image, 1 / 255.0, (416, 416), swapRB=True, crop=False)
net.setInput(blob)
detections_layer = net.forward(layer_names) # detect objects using object detection model
detections_bbox = [] # bounding box for detections
boxes, confidences, classIDs = [], [], []
for out in detections_layer:
for detection in out:
scores = detection[5:]
classID = np.argmax(scores)
confidence = scores[classID]
if confidence > yolomodel['confidence_threshold']:
box = detection[0:4] * np.array([W, H, W, H])
(centerX, centerY, width, height) = box.astype("int")
x = int(centerX - (width / 2))
y = int(centerY - (height / 2))
boxes.append([x, y, int(width), int(height)])
confidences.append(float(confidence))
classIDs.append(classID)
idxs = cv.dnn.NMSBoxes(boxes, confidences, yolomodel["confidence_threshold"], yolomodel["threshold"])
if len(idxs)>0:
for i in idxs.flatten():
(x, y) = (boxes[i][0], boxes[i][1])
(w, h) = (boxes[i][2], boxes[i][3])
if (labels[classIDs[i]] == 'bicycle'):
detections_bbox.append((x, y, x+w, y+h))
clr = [int(c) for c in bbox_colors[classIDs[i]]]
cv.rectangle(image, (x, y), (x+w, y+h), clr, 2)
cv.putText(image, "{}: {:.4f}".format(labels[classIDs[i]], confidences[i]),
(x, y-5), cv.FONT_HERSHEY_SIMPLEX, 0.5, clr, 2)
objects = tracker.update(detections_bbox) # update tracker based on the newly detected objects
for (objectID, centroid) in objects.items():
text = "Num {}".format(objectID)
if (int(format(objectID)) > bicycle):
bicycle = int(format(objectID))
text2 = "Total %d "%(bicycle+1)
cv.putText(image, text, (centroid[0] - 10, centroid[1] - 10), cv.FONT_HERSHEY_SIMPLEX,
0.5, (0, 255, 0), 2)
cv.circle(image, (centroid[0], centroid[1]), 4, (0, 255, 0), -1)
cv.putText(image, text2, (30, 30), cv.FONT_HERSHEY_SIMPLEX,
1, (0, 0, 255), 3)
cv.imshow("image", image)
if cv.waitKey(1) & 0xFF == ord('q'):
break
if writer is None:
fourcc = cv.VideoWriter_fourcc(*"MJPG")
writer = cv.VideoWriter("output-bicyle.avi", fourcc, 30, (W, H), True)
writer.write(image)
writer.release()
cap.release()
cv.destroyWindow("image")
Cette fois je compte en double des cyclistes, je pense qu’avec plus d’images par seconde je n’aurai pas eu le problème. J’ai un total de 280 cyclistes.

 Mon modèle est le suivant :
Mon modèle est le suivant :
yolomodel = {"config_path":"../pretrained_models/yolo_weights/yolov3.cfg",
"model_weights_path":"../pretrained_models/yolo_weights/yolov3.weights",
"coco_names":"../pretrained_models/yolo_weights/coco.names",
"confidence_threshold": 0.5,
"threshold":0.3
}
Si je change de modèle pour mettre :
yolomodel = {"config_path":"../pretrained_models/yolo_weights/yolov3.cfg",
"model_weights_path":"../pretrained_models/yolo_weights/yolov3.weights",
"coco_names":"../pretrained_models/yolo_weights/coco.names",
"confidence_threshold": 0.6,
"threshold":0.4
}
Le résultat est le suivant : 238 cyclistes (à la place de 280).
 Si je continue d’augmenter de la facon suivante :
Si je continue d’augmenter de la facon suivante :
yolomodel = {"config_path":"../pretrained_models/yolo_weights/yolov3.cfg",
"model_weights_path":"../pretrained_models/yolo_weights/yolov3.weights",
"coco_names":"../pretrained_models/yolo_weights/coco.names",
"confidence_threshold": 0.75,
"threshold":0.5
}
Le résultat est le suivant : 209 cyclistes, je pense que c’est proche de la réalité.


Quand j’ai 0,75 je détecte de facon plus proche et j’ai donc moins d’erreur sur le suivi du numéro. Par contre ensuite j’ai à nouveau des doublons si j’essaye d’augmenter encore la valeur.
A suivre.
J’aime ça :
J’aime chargement…

 Bref c’est pas le top. J’ai donc lancé winecfg pour modifier et passer de Windows 7 à Windows XP.
Bref c’est pas le top. J’ai donc lancé winecfg pour modifier et passer de Windows 7 à Windows XP.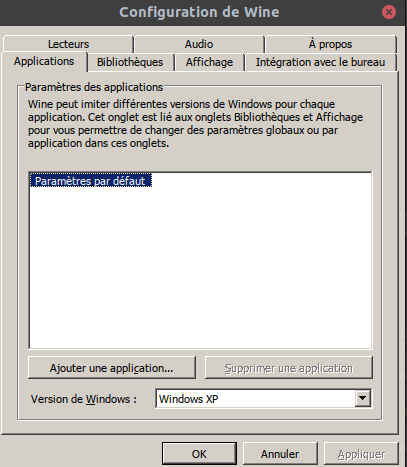 Avec Windows XP pas de lancement de iTunes, j’ai donc mis Windows 8.1 et Windows 10 (toujours noir).
Avec Windows XP pas de lancement de iTunes, j’ai donc mis Windows 8.1 et Windows 10 (toujours noir). Crash …
Crash …


