J’ai pu voir des appels à l’API : api.ipify.org
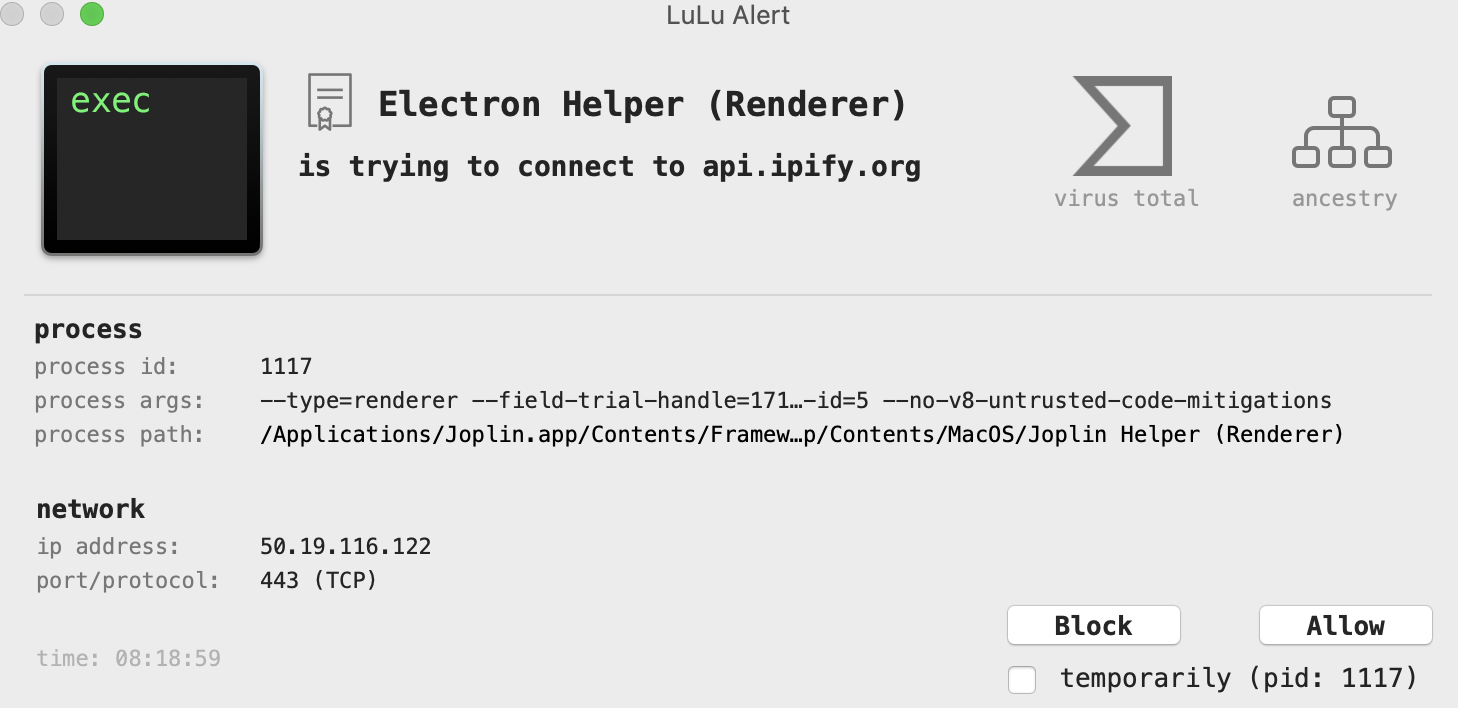
Il y a donc l’utilisation d’une API pour la géolocalisation des IP. Je sais pas si c’est très bien …
A suivre.

J’ai pu voir des appels à l’API : api.ipify.org
Il y a donc l’utilisation d’une API pour la géolocalisation des IP. Je sais pas si c’est très bien …
A suivre.
My script to rename tacitpart file :
#!/bin/bash
# ARIAS Frederic
#
# For MAC OS do
#
suffix=".tacitpart"
path="WebDAV"
for file in $path/*.tacitpart
do
if [[ -f $file ]]; then
filenew=$(basename $file $suffix)
echo $file" -> "$filenew
mv $file $path/$filenew
touch $path/$filenew
fi
done
#
for file in $path/.resource/*.tacitpart
do
if [[ -f $file ]]; then
$filenew = ${file/%$suffix}
echo $file." -> ".$filenew
mv $file $path/.resource/$filenew
touch $path/.resource/$filenew
fi
done
J’ai découvert ce superbe logiciel : Joplin, et je l’ai utilisé de façon intensive jusqu’à ce que le WebDav en HTTP ne soit plus possible. Ensuite cela a été la galère pour synchroniser les notes. J’ai cru pendant un moment que le problème allait être rapidement corriger … mais non. Mon précédent POST sur le problème : https://www.cyber-neurones.org/2019/07/android-joplin-synchronisation-webdav-en-http-est-hs/ . Le problème est ouvert depuis le 17 juin, et on est le 8 septembre …
J’ai donc cherché une autre solution, c’est de faire la synchronisation via un logiciel tier sous Android : FolderSync . Mais la solution ne fonctionne pas, et je ne sais pas pourquoi …
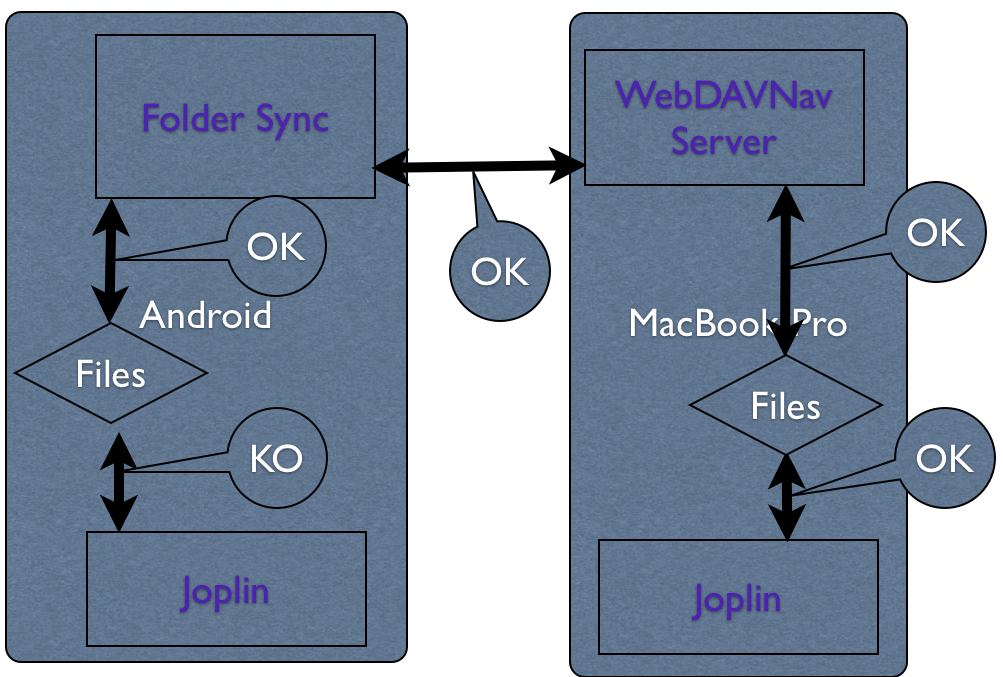
Sur Folder Sync, j’ai bien le répertoire : /store/emulated/0/Joplin qui est complet :
Sur Joplin je pointe bien sur le même répertoire :
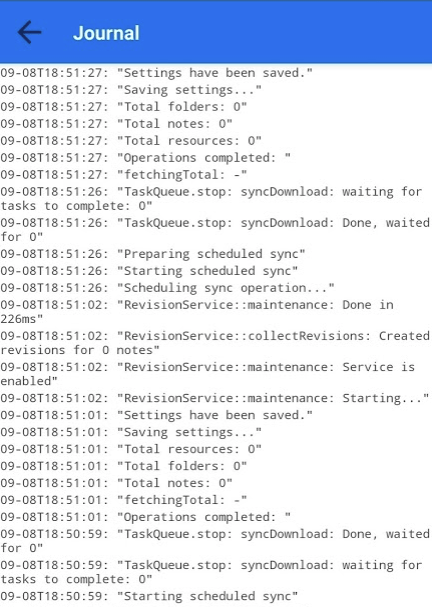
Misère.
UPDATE : SOLUTION :
J’ai effacé complètement Joplin, et j’ai relancer mon portable. Ceci a fixé mon problème … Bizarre. ( Le lien vers le POST sur le forum : https://discourse.joplinapp.org/t/android-issue-with-sync-by-file-system/3448 ).
Depuis deux versions il est impossible de faire une synchronisation via WebDAV , j’ai même essayé avec une clef privé ou une clef publique mais cela n’a pas fonctionné.
Les deux versions de Joplin pour Android (je conseille donc de ne pas faire la mise à jours) : https://play.google.com/store/apps/details?id=net.cozic.joplin&hl=fr
J’ai ouvert un ticket mais dans réelle solution : https://discourse.joplinapp.org/t/webdav-not-work-with-last-release-of-android/2696 :
Hi,
Since the last update of Joplin, I can’t sync with WebDAV.
I put a tcpdump on port of WebDAV but I don’t see any request … I try to remove and reinstall the app, but I have a same issue.
How I can have more logs on Joplin (Android) ?
Thanks.
Frédéric.My release on Android 1.0.271.
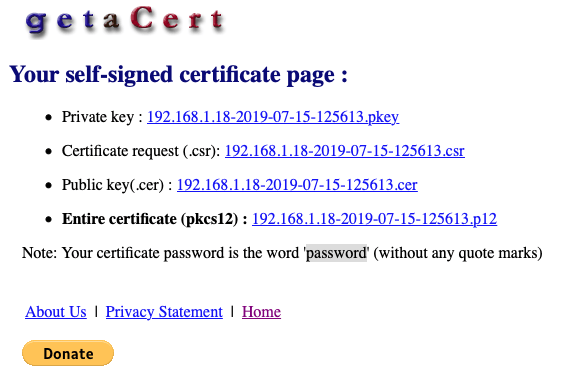
La clef publique qui ne fonctionne pas :
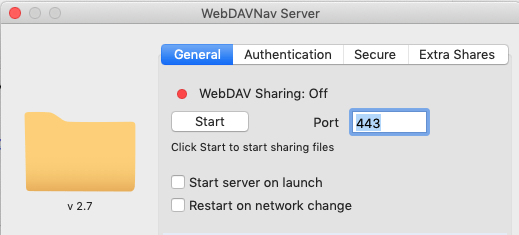
Le logiciel que j’utilise sur mon mac WebDAVNav Server v2.7:
J’ai tout essayé :
Le problème semble être connu : https://github.com/facebook/react-native/issues/25244 … c’est sur react-native : https://github.com/facebook/react-native .
Le problème est toujours ouvert : https://github.com/laurent22/joplin/issues/1686 : WEBDav sync in Android version cannot be performed.
Misère, je suis bloqué depuis 30 jours.