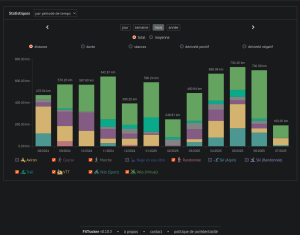
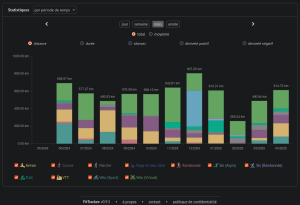
Mon instance FitTrackee est UP à nouveau : https://fit.cyber-neurones.org/
Mon env.cfg :
export FLASK_SKIP_DOTENV=1
export HOST=0.0.0.0
export PORT=5000
export CLIENT_PORT=3000
export APP_SECRET_KEY=...
export APP_LOG=/home/XXXX/fittrackee/fittrackee.log
export UPLOAD_FOLDER=/home/XXXX/fittrackee/uploads
export DATABASE_URL=postgresql://fittrackee:XXXXXXX@localhost:5433/fittrackee
export UI_URL=https://fit.cyber-neurones.org/
export DEFAULT_STATICMAP=False
export STATICMAP_CACHE_DIR=/home/XXXX/fittrackee/staticmap_cache
#export TILE_SERVER_URL=https://tile.openstreetmap.org/{z}/{x}/{y}.png
#export TILE_SERVER_URL=https://a.tile.openstreetmap.fr/hot/{z}/{x}/{y}.png
#export MAP_ATTRIBUTION='OpenStreetMap contributors'
export TILE_SERVER_URL=https://tile.thunderforest.com/outdoors/{z}/{x}/{y}.png?apikey=XXXXXXXXXX
export MAP_ATTRIBUTION='Thunderforest'
Il m’a fallu ajouter STATICMAP_CACHE_DIR pour fixé le problème.
Dans les logs j’ai testé 3 configurations du TILE_SERVER_URL mais à chaque fois j’avais la même erreur :
.... 2025/07/06 17:19:11 - staticmap3.staticmap - ERROR - request failed [None]: https://c.tile.openstreetmap.fr/osmfr/11/1065/748.png ... 2025/07/06 17:42:18 - staticmap3.staticmap - ERROR - request failed [None]: https://tile.openstreetmap.org/17/67885/47864.png ... 2025/07/06 18:17:33 - staticmap3.staticmap - ERROR - request failed [None]: https://tile.thunderforest.com/outdoors/17/67885/47863.png?apikey=.... ...
En fait l’erreur indiquer un problème d’enregistrement et pas un problème de téléchargement.
La taille actuellle :
# du -sh /home/XXXX/fittrackee/staticmap_cache 9,5M /home/XXXX/fittrackee/staticmap_cache
Ce qui est bizarre, c’est que la valeur par défaut est .staticmap_cache . Mais je ne le trouve pas dans :
-/home/XXXX/fittrackee/.staticmap_cache
-/home/XXXX/.staticmap_cache
-/.staticmap_cache
…
Bref c’est cool d’avoir trouvé la solution et moins bien de ne pas avoir compris.